|
如果我们回看整个智能汽车系统架构的演进过程,汽车的电子电气架构经历了“直联”,“总线”,“域控”三个阶段,从离散走向集中,构筑了硬件架构变化的“三部曲”。
有意思的是,软件架构的发展过程,也存在着类似的变化。
当下数据驱动的“自学习型”智能驾驶系统得到了行业越来越多的认可,整个学习系统的构建也经历了三个阶段。从传统学习系统,到当下行业主流的分布式深度学习系统,再到以特斯拉为代表的集中式深度学习系统,构建了软件架构变化的“三部曲”。
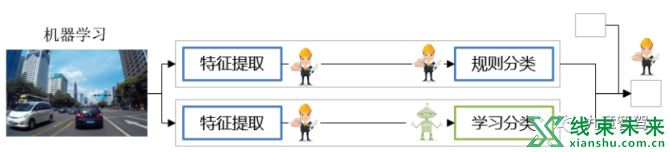
传统学习系统
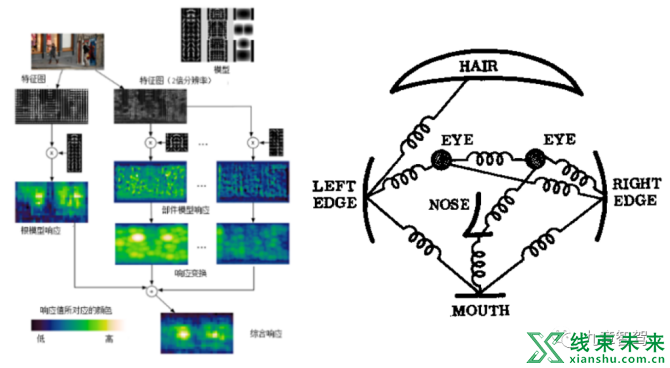
首先就是传统学习系统, 主要由传统机器学习和规则算法构成, 一个典型的例子就是DPM算法。其通过采用改进的HOG特征(人工设计特征),SVM分类器和滑动窗口(Sliding Windows)检测,配合多组件(Component)外加图结构(Pictorial Structure)的检测框架(类似下图的多弹簧结构)来完成检测。此类方法使用了一部分规则算法,同时使用了一部分浅层的机器学习算法。
对于这一类系统,与其说这是数据学习系统,更不如说是工程师学习系统。 实际上,在规则主导的算法系统里,真正获得成长的是工程师而不是系统。 如果把学习比作考场答题,那传统机器学习和规则算法阶段更像是直接把答案连同考题一起打印出来,打印机并没有在这个过程中学习到任何东西。因此规则算法为主的系统,很难界定它为真正意义上的学习系统。
分布式深度学习系统
分布式深度学习系统主要由多个独立的深度学习网络构成。深度学习原理的资料网络上较多,这里简单介绍,不做扩展。
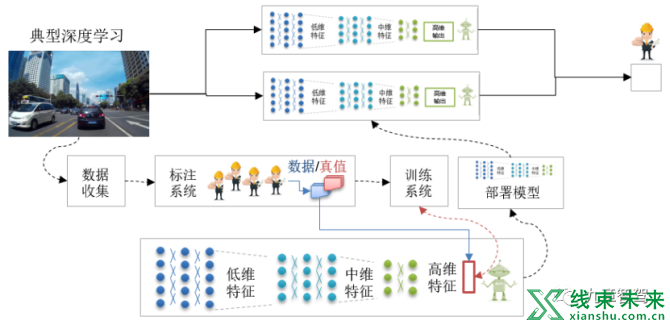
深度学习属于机器学习的一种,但不同于传统机器学习算法,其可以满足更为复杂的学习任务。一个标准的有监督深度学习训练,主要由如下几部分组成:原始数据样本与对应的真值,网络模型结构(先验)以及对应的损失函数(目标)。深度学习常用的训练方法是梯度下降和反向传播,其训练过程涉及epoch/iteration/batch等关键参数的选取,初值以及最优化器的选择。
另外,训练完成后的评估阶段,往往通过交叉验证等方法,发现欠拟合或过拟合等训练问题,跟踪模型的泛化性能力。通过方差与偏差或者第一二类错误等指标,评价模型的业务匹配度,并根据需求找到不同指标间的平衡,依照评估结构重新调整模型结构与训练过程。
深度学习虽被叫做“炼丹”,但各种要素之间也有其基本关系。整个学习过程中,数据的质量和数量大体决定了模型的性能,模型结构则决定了模型效果的上限,而训练过程决定了逼近上限的速度与程度。
面对复杂的训练过程,还需要配置更多的外围系统,比如数据预处理系统(负责数据的生产,清洗和增强),训练评估管理系统(负责模型迭代基线的管理,超参调整管理,复杂模型评估等),数据部署系统(将模型从云端适配到业务终端)。
目前典型的深度学习(有监督学习系统)可以说是一个真正意义上的可学习系统, 其具有完整的数据收集、真值获取、网络训练和模型部署的过程环节。也是目前智能驾驶正在采用的主流方案。
但这种方案也在面临困境,和分布式EEA架构一样,问题就出现在“分布”两字。虽然各家的模型设计细节或者具体数据管道细节各不相同,但基本上都是多个有监督训练网络的独立部署。
车道一个网络、障碍物一个网络、信号灯一个网络。每个网络都需要大量人工标注,且不同的标注数据都只能服务一个功能,不同数据之间缺少相互的贡献。
还是以考场答题为例,虽然这次确实是一个学生正儿八经地根据自己所学完成了这一次测试,可是其解答考题的方式更多是对相似的题库,甚至考卷答案进行强制记忆,是一种典型的“鹦鹉学舌”。
一个有意思的现象是,任何智能体包括人类在内都深知“偷懒”的重要性。 如果通过背诵答案和学习真正的知识点都能够使自己通过考试(收益相等),智能体更愿意选择前者,也就是说在分布的学习系统当中,由于网络只解决单一的任务,其便没有动力去学习多个任务背后的共性特点。从而很大程度上致使其遗漏了部分“重要的知识”,我们在后续内容中会具体展开这个过程。
为了解决分布式深度学习系统的困境,集中式深度学习系统开始出现。
集中式深度学习系统
集中式深度学习的构成仍然是深度学习网络, 然而不同于分布式最大的特点主要表现在两个方面, 1. 云端训练以及车端部署往往采用单一网络架构。2.训练手段逐步开始采用弱监督或者自监督方法。
在工程实践中我们会发现,人工智能不可能在脱离人类支持和控制的情况下,完成自我成长。但纯粹依靠人类的标注,也无法达到人工智能持续成长所需的数据体量。因此,在很长一个周期内,智能驾驶的发展必然会围绕弱监督系统展开。
也就是说,有监督学习、弱监督学习以及自(无)监督学习会长期并存。有监督学习是智力的“酵母”,而弱监督与自监督学习则是一个持续发酵的过程。
相比有监督学习的填鸭式启蒙教学,弱监督学习更像是业务专家对学习系统的“点拨”,而自监督则更多是师傅领进门后的个人修行。人类工程师逐级往后提供更少、更高维度且更为抽象的输入来指导学习系统的成长。
深入分析上述两类学习系统的实践经验, 我们会发现几个关键痛点:
为了应对以上这些痛点,基于多任务弱监督的深度学习系统初见端倪,特斯拉在其“Data Pipeline and Deep Learning System for Autonomous Driving”的专利基本描述[0011]条上,做了如下解释:其将感知提取作业作为单独的数据组件(components),使用多层来实现网络结构;将传感器数据提取为两个或更多个不同的数据分量。
例如,不同局部特征数据可以与全局数据分解为不同的数据成分;不同的数据组件提取数据以确保在机器学习网络的适当阶段与位置进行准确的特征检测。对不同的数据分量可以进行预处理以增强它们所包含的特定信号信息。数据分量可以被压缩/或下采样以增加资源和计算效率。 从这份专利描述和相关联的信息中,我们可以隐约看出特斯拉正在采用的学习系统,极大概率就是使用了自监督的框架的集中式深度学习系统。
自监督下的集中式深度学习系统详解
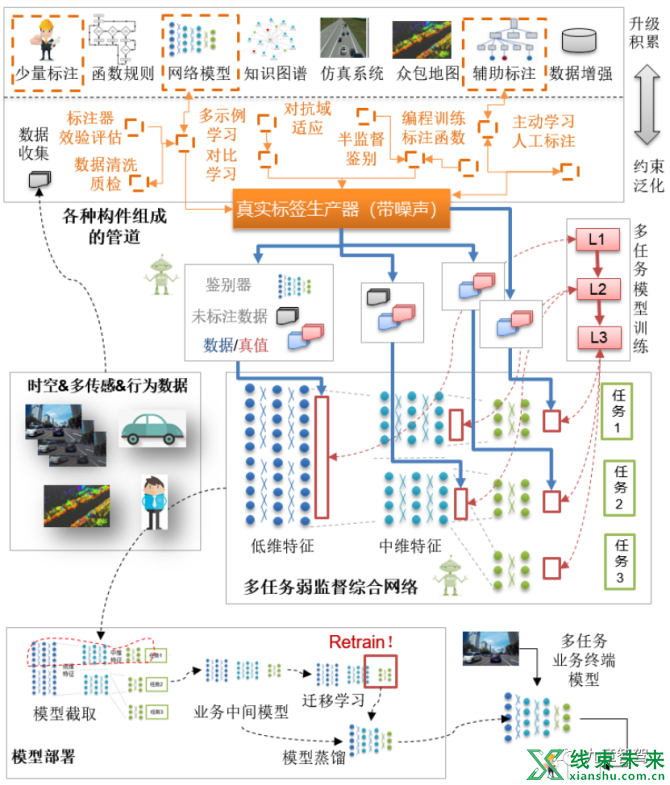
下图对整个自监督学习系统的构成做一个介绍。 我们会发现其和经典的深度学习系统还是有着巨大的区别。
在各类文章中大家一定听到过好多深度学习名词,比如有监督、标注辅助、对比学习、迁移学习、增强学习、半监督学习等等。实际上结合智驾业务模型,我们能看到这些时下流行的名词是如何被有机整合在一起,并解决传统学习系统痛点的。毫不夸张的讲,自监督学习系统,在未来必然是整个智能驾驶闭环系统最为核心的部件。
自监督学习给工具链带来的变化
与传统深度学习系统类似,整个学习系统分为数据采集、数据处理、训练、核心云端网络设计、模型部署和最终集成等几个基本环节。
1)数据采集
首先是车端采集策略的变化。
过去由于更多依赖人工标注,因此采集需要被标注的输入(一般为图片)就基本满足数据搜集的要求,剩下的交给标注人员即可产生训练所需的真值。但在自监督学习系统下,如果我们需要更好地发现数据之间的关联,就需要同时采集图像外围的关联数据,比如,在时间维上将图像记录变为视频记录,在感知维上增加了额外的其他传感器以及过程语义信息的记录,部分间接真值数据(紧急刹车,检测失效,用户退出)也会被保存。
同时借由车端差异收集系统,对价值数据做初步过滤。特斯拉目前已经采取了类似的策略,其使用车上8个摄像头的视频流数据进行标识,想比上一代系统效率提升了三个数量级。
视频以及其他时间序列的记录可以支持模型通过过去的序列预测未来的序列,多传感器的接入可以增加更多效验渠道,并提供跟多泛化回路。语义模型可以反映场景状态更好地和司机行为关联,发现潜在的标签,从而将庞大体量的司机数据转化为价值。采集策略的变化重点是增加潜在的关联信息量,从而为后续自监督系统可以正常工作提供基础。
2)数据标注
数据上传后对学习系统而言,最关键的就是真值数据的标注。
伴随着深度学习网络的延伸,原来由规则算法处理的视觉测距、融合、地图、预测甚至规划都开始使用深度学习方法。因此真值的定义也逐步扩大。
深度学习测距的成熟以及规则算法对俯仰角抖动问题的无奈,促使行业开始从2.5D标注转向4D的标注,实际上是用三维空间加时间维的标注方法代替传统图像2D标注+深度或者类型标注,甚至出现了5D、6D等更多维度的标注需求。当然,3D的障碍物标注以至于更高维的标注已经逐渐超出了人类可接受的范畴。
因此配合业务需求的升级以及数据采集标准的升级,真值标注系统的概念也已经发生变化。过去的标注是一个劳动密集型行业,有标注工具以及标注人员就可以开通。而当下的标注已经逐步变成一个综合性极高的业务,成为技术密集型行业。
半自动标注或者全自动化标注系统的设计范式已知的就有三十多种,从原来的图像真值标注演化为一个更为广义的概念,也就是如何为智能驾驶各个模块的优化迭代提供直接或者间接的学习素材。包括主动学习、半监督学习、编程标注、众包、仿真迭代等。
无论采用何种手段,这个模块的功能定位是明确的,就是为被训练模块提供一种抽象意义上可能带有噪声的“真值标签”。
只不过过去只有人工标注,而当下可用的手段和存在形式就丰富了许多,对抗网络、无标注数据、数据增强、辅助标注,甚至另一个网络模型都可以成为一个生成“真值”的系统。
3)模型训练
紧接着我们要讨论的是云端训练模型设计,其实施逻辑与经典方法有着诸多不同。
过去不同的业务(障碍物检测、车道检测)都会采用独立的模型,在控制训练稳定性上要优于有多个任务目标的多头多任务模型,但这种简单训练方法有着较为致命的问题——和整车,电子电气架构一样,网络学习模型也在走向集中化。因为孤立的网络模型无法更有效的利用数据“能量”且同样缺少灵活性。
仍然是考场答题的例子,如果通过考试是我们唯一的考量维度,你选择把试卷隐含的所有知识点都理解透彻后参加考试?还是直接把答案背诵下来参加考试?一个理性人都会选择后者,因为大脑本质上是“懒惰”的,希望使用最小的能量和复杂度完成目标。
而这种懒惰的代价就是每个业务都要重新组织数据,过程笨拙无比。训练出来的网络无法解释自己,且多次业务迭代后也不会有持续的积累。这种情况和之前讨论的电子电气架构的变革原因是类似的。
新的网络结构则更倾向于前者,倾向于一个大型的集中网络,但是会在整个网络的不同断面(主干层,分支层,支线层)逐层进行训练,并同时训练多个任务(multi-task learning)。这些不同断面,不同任务的联合训练,实际上是一种对神经网络的“逼迫”。
简单地理解,就像是一份试卷不仅要你答案准确,还需要用几种解题思路完成,并对你的各种中间过程做出要求。
这时,哪怕最懒惰的大脑也会发现,理解知识点变成最为“节能”的方法。这也促使网络模型学习到真正的知识,各个层次与分支也拥有了“规则组件”的可拆解性,增强了网络模型的可解释性。不同层次可以根据需求使用不同的标签生成器,前一层网络的训练结果甚至可以反过来结合各种真值生产构件,为后一层的网络模型的真值服务。
我们会发现在这种集中式结构下,数据的积累,模型的可解释性以及多业务的转移成本都有了质的变化,当然和讨论域控制器的优劣一样,这种多个维度都有所改善的设计,都是以提升工程师能力为前提的,这类网络、数据、训练以及任务管理相比过去都更加难以运维和控制。
4)算法部署
在部署阶段,根据业务场景的输入输出要求,可以对云端大型网络进行阉割,保留关联的连接结构以及业务所需的输出。
同时,可以使用迁移学习的思想,根据需求将网络模型的部分参数结构锁定,作为模型的“预训练”成果,在感兴趣的实车任务上进行 “微调”。或者利用蒸馏学习的思想,用云端模型训练一个车端更紧凑的模型,满足车端的算力和业务要求。
相比于过去,在实际业务场景发生时,已经不是数据和模型的推倒重来,而是重新完成一次,真值标签的生成,多任务的训练,网络模型的阉割和最终的部署压缩。为新业务增加的投入和成本是可控的,且有可能还会为下一个业务作出贡献。这种集中化带来的优势,和域控制器的逻辑是非常类似的。
如果域控制器提供了完整的肉身,则当下弱监督多任务的学习系统则提供了可期的灵魂。到这里整个智能驾驶系统的“类人结构”便初见雏形。
总结
总的来说,智能驾驶学习系统的演进是“机器人”视角下对“学习”这个概念的理解加深。
传统学习系统中,“机器人”没有学到太多内容;在分布式学习系统中“机器人”学习到了一些表层的现象,但缺少对共性的理解;在集中式学习系统当中,“机器人”则被迫从多个现象中学习背后的共性知识;而学习系统的设计者则更像是一个老师,希望引导学生去掌握真正有价值的东西。
另外如果我们将整车电子电气架构比作人类的身体,则域控制器的革命,是将零散的身体部件组织成一个完整的身体;而集中式深度学习系统更像是将零散的脑组织,组织成一个完整的大脑。这些都是机器走向“类人结构”的一个必经过程。 免责声明:本网站的部分内容,来源于其他网站的转载,转载目的在于传递和分享更多信息,并不代表本平台赞同其观点和对其真实性负责,版权归原作者所有,如有侵权请联系我们删除。 |